摘要
MapReduce是用于大规模数据的新的编程模型,map对KV数据进行处理,生成中间KV结果,reduce对中间结果按照KEY进行分组操作。
简介
随着互联网的发展,数据量出现了迸发式的增长,如何对如此大规模的数据进行分布式存储?如何基于这些数据进行并行计算?如何处理计算过程中的故障问题?
为了解决基于大数据量、普通PC机器的大规模计算问题,可以将所有的计算单元抽象为map和reduce连个原子操作的集合。通过用户自定义的map和reduce的函数模型,我们可以实现执行单元的并发执行,以及良好的容错机制。
编程模型
计算的操作对象都是KV模型,用户只需要编写map和reduce函数即可实现编程。
示例
- map函数
|
|
- reduce函数
|
|
实现
执行流程
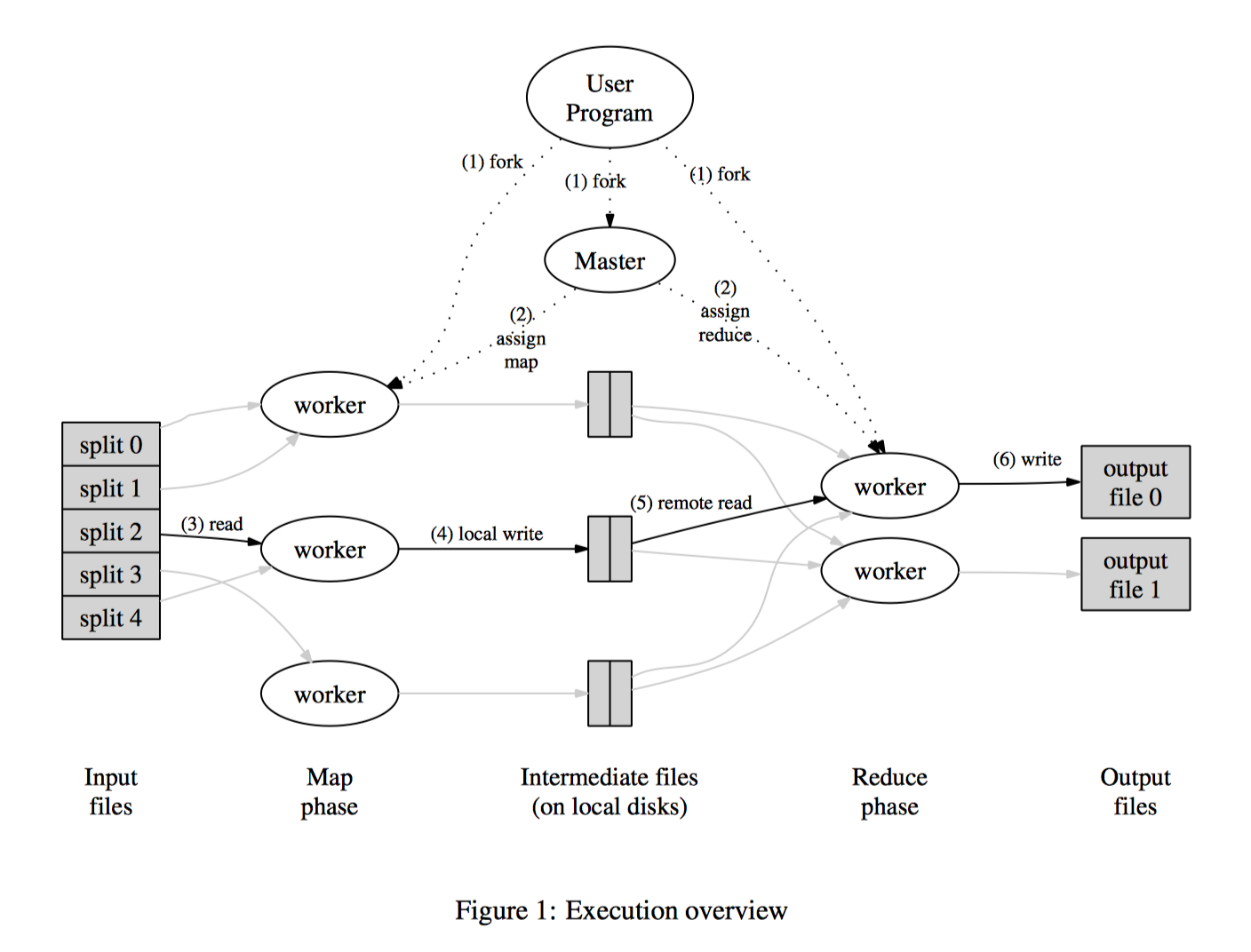
- 讲输入进行分片,分片的基本单位是64MB
- 程序fork出一个master和几个worker,master分配任务给worker,master挑选空闲的worker,分配map或者reduce任务进行执行
- 执行map的worker读取分片的输入,应用用户的map程序,生成的中间KV结果集缓存在内存中。
- 内存中的中间结果定期的按照HASH KEY的分区写到本地磁盘。
- master唤醒reduce的worker,通过RPC读取map相应位置的中间结果;reduce会首先对中间结果进行排序操作,如果内存不足,会导致外排。
- reduce worker遍历中间结果,应用用户的reduce函数。
- 所有的map和reduce tasks执行结束,master将控制权交给用户程序。
Master数据结构
master管理map和reduce task的状态,以及worker machine的状态。
master将map产生的中间结果的位置,传递给reduce worker。
容错
worker failure
master定期ping各个worker机器,如果在规定时间内不返回的话,认为此机器宕机了。
- 任何执行完成的map task会重置为idle状态,被重新执行。
- 任何在执行中的map和reduce task会被重置为idle状态。
- 已经执行完成的reduce task不会被重新执行。
master failure
可以通过周期性的做检查点,来恢复master故障,但是考虑到master只有一个,很少出现故障,因此如果master宕机,这里选择放弃当前任务的策略。
出错的处理
如果用户的map和reduce函数是确定性函数,则其结果集也是确定的。
不会存在map的中间结果被重复执行的情况。master会忽略相同的map输出结果。
也不会存在多个相同的reduce操作同时进行,因为reduce的结果会先生成临时文件,然后执行rename操作,rename操作是原子的,如果多个相同的reduce执行rename操作,只有一个会成功。依赖的GFS底层的原子rename操作。
本地计算
带宽是mapreduce集群非常重要的一个因素,尽量讲map下放到和其分片数据在一台机器上的worker。尽量减少数据在网络的传输。GFS中的数据存在3个副本,master会尽可能利用副本所在的机器分配worker。
任务粒度
已经将map分为M片,reduce分为R片。应该让M和R远远大于worker机器,这样每个worker可以分配更多的任务,任务粒度更低,任务调度更加准确,更有利于集群机器的负载均衡。
备份任务
很多作业的最终任务集中在几个大的reduce上,而这几个大的reduce可能因为机器原因往往导致执行特别慢。
我们提供备份任务的机制,当MR任务进入最后的快要结束状态,master备份各个task的状态,并利用其它worker去执行未完成的task,这样,不管是主的任务还是备份任务,只要有一个完成,整个任务就算结束了。
经过我们的实际统计的数据,可以知道,关闭backup策略后,执行时间普遍增加44%.
优化
分区函数
默认的分区函数是hash(key)的方式,一般来说,数据会比较均匀,当然也存在特殊情况。MR库提供特殊的分区函数,如hash(Hostname(urlkey))
中间结果排序
保证每个partiton的key按照升序排列,有利于后续需要排序的操作。
Combiner函数
允许每个partition进行提前合并,在map之后,在reduce之前,比如单词统计中,(“the”, 1)肯定有很多,可以先统计成(“the”, N), 再传递给reduce
副作用
尽量减少手动生成临时文件,因为无法保证多个文件的原子性提交。
跳过错误记录
由于程序或者数据问题,引起部分task异常的时候,可以选择性的忽略对这些数据的操作。
本地执行
由于分布式系统的不确定性,提供了本地执行的方式,所有的任务在一台机器上顺序执行,并提供了类似gdb的工具进行调试。
个人观点
mapreduce开启了一种新的对于打数据量进行分析的编程方法,但是存在几点不足。
- 对同一份数据的不同分析,需要写不同的map和reduce任务
- 场景基本是离线分析,不适用于用户交互场景
所以目前出现了各种SQL On Hadoop的技术,SOH技术可以解决第一个问题, 将SQL转化为对应的MR job。
但是对于第二个问题,需要彻底颠覆目前的计算框架以及底层存储结构GFS。
这也是目前Google F1出现的原因吧, HATP可能才是正确的方向。