什么是lease?
client write请求之前需要申请一个lease,类似于一个锁,此锁有超时时间,如果client需要持续更新的话,需要定期renew lease,达到长期占有写锁的期望。
如果client lease到期,但是没有正常close文件,那么master就会强制关闭client的连接,并对之前client操作的replica进行lease recovery.
lease recovery
lease recovery是client过了lease的租期后,被master回收写权限,同时需要对之前client的写操作进行处理的过程。
- 获取涉及文件f的最后一个block的所有datanode节点。
- 指定其中一个节点作为主节点p
- p从master获取新的generation stamp
- p从各个datanode获取block info
- 计算所有datanode节点last block的最小长度
- 更新所有的datanode,以最小长度作为block长度
- 通知master更新block信息
- master更新block信息
- master清除client的lease,让其它client可以进行写入操作
- master写WAL
HDFS write pipeline
HDFS为了达到高可用,一条数据会写多个副本,写数据采用了pipeline方式。
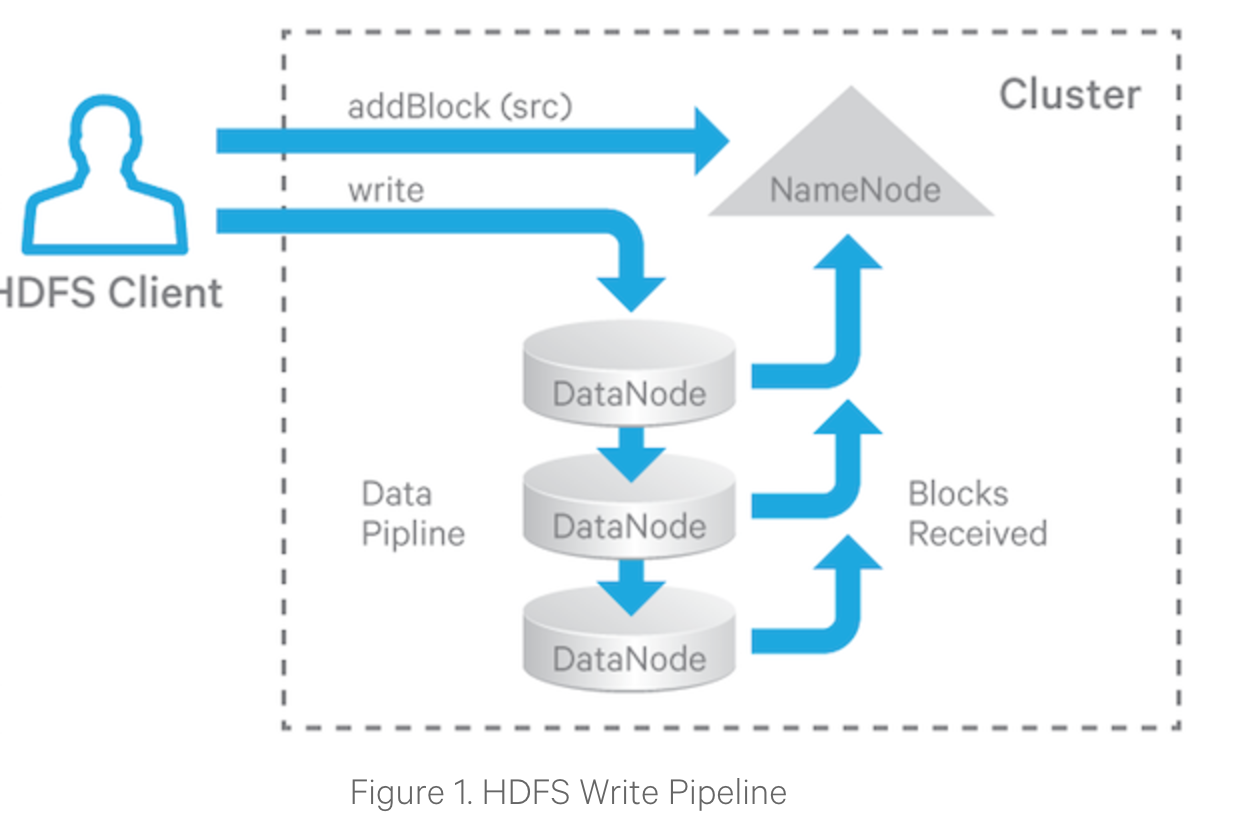
管道写的三个流程:
- Pipeline setup.客户端给datanode发送写请求,pipeline最后一个datanode返回响应才算成功
- Data streaming.客户端将写操作缓存,buffer满或者调用了flush之后,缓存数据才会写到datanode
- Close. 结束写入,等待所有datanode写入完成的通知,然后发送close命令给datanode,datanode接收到命令后,将状态设置为FINALIZED.
DataNode recovery
Recovery from Pipeline Setup Failure
- 如果是申请写新的block失败,则向master重新申请新的block,以及新的datanodes列表。
- 如果是写老block失败,则用正常的datanodes重建datanodes链表,并更新generation stamp
Recovery from Data Streaming Failure
- 当某个datanode出现问题,比如宕机或者磁盘故障,所有的TCP/IP连接都会断开。
- client感知某个datanode故障,停止发送写请求,利用正常的datanodes重建datanodes链表,同时更新GS
- client重新发送buffered data。如果一些datanode已经接受过此数据,则此datanode只会作为数据的跳板,不再重复写入,而是讲数据顺序下发。
Recovery from Close Failure
- client重建datanode链表,每个datanode提升GS,同时没有进入FINALIZED状态的进入FINALIZED状态
个人思考
- datanode的写入是通过pipeline方式管道写入,性能存在瓶颈
- 故障恢复依赖了master和client的相互作用
- 如果第一次三个节点失败,需要client请求重建datanode,重新写请求
- 可以借鉴raft、paxos等一致性协议,多数写入成功就算成功,避免client频繁与datanodes交互