引入原因
Google索引系统上百PB的数据量,每天更新量在数十亿。目前使用了bigtable进行存储,但是更新效率不高,MR基本用于全量更新。故开发了Percolator系统,用于增量数据的更新。
架构
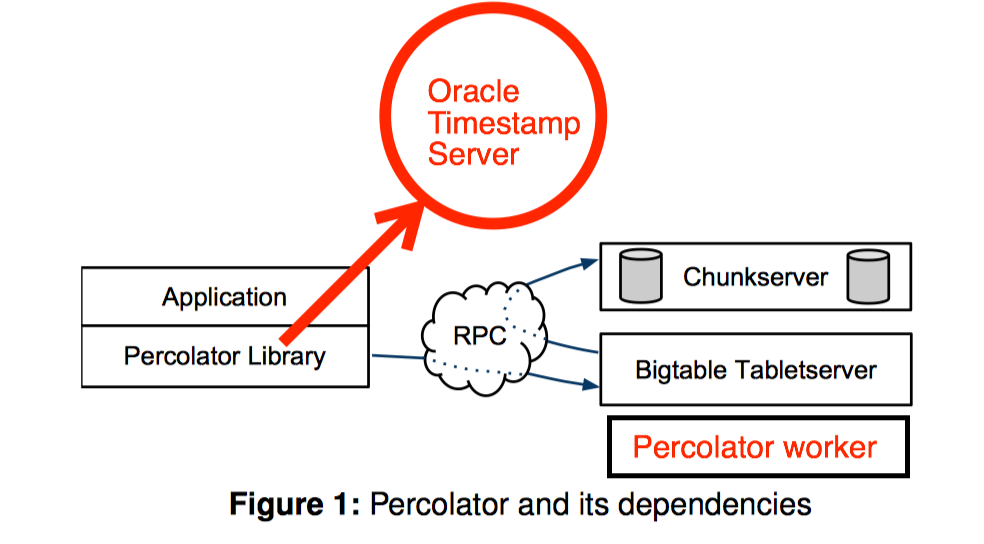
主要组成部分
- Percolator library: 以第三方动态库的形式提供给app,
- Oracle Timestamp Server: 提供全局递增唯一的时间戳
- BigTable TabletServer: 底层逻辑存储,类似HBase
Percolator的特点:
- 提供跨行跨表的分布式事务
- 提供OB框架
分布式事务
- 实现了Snapshot的隔离级别
- 使用2PL+MVCC技术
- 存在并发写冲突时,最多一个提交,也可能存在全部回滚的可能
- 读不上锁,根据时间戳读取历史版本。
- 2PC,首先prepare,然后commit
- 缓冲写。写都缓存在client端,只有提交的时候才真正和bigtable交互。
MVCC基本逻辑
写入举例
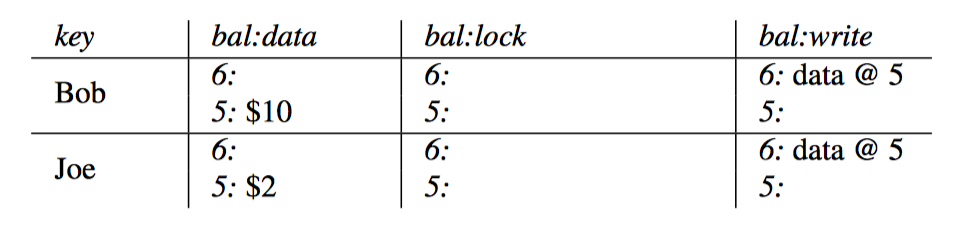
每行数据引入新的列:lock和write.
- lock用于写入新数据之前的上锁
- write用于表示事务提交,write的value记录了本次写入的时间戳
Note: bal:data表示真是数据,bal:lock表示锁,bal:write表示最后提交的数据对应的版本号。
以Bob给Joe转账$7为例进行说明
- 初始状态, Bob的bal:lock为空,bal:write为@5,表示数据的版本是@5,故Bob的钱是5:$10。
- 对bob账户执行扣款操作,首先锁定,并将data减少为$3.
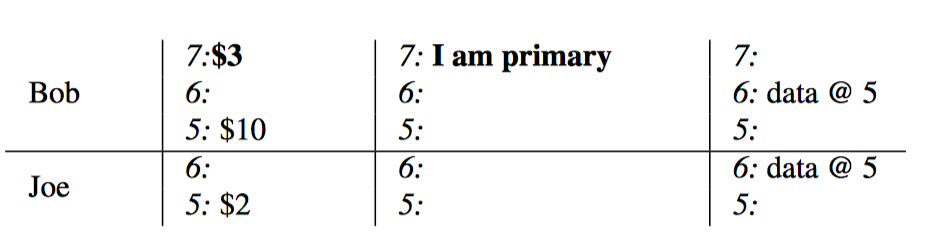
- 对Joe账户执行加钱操作,首先锁定,并讲data增加为$9, lock里面记录的值为第一个lock的位置,便于将锁串联起来

- 此时达到了commit阶段,写入新的记录bal:write列表示commit结束,之后清理所有的lock。
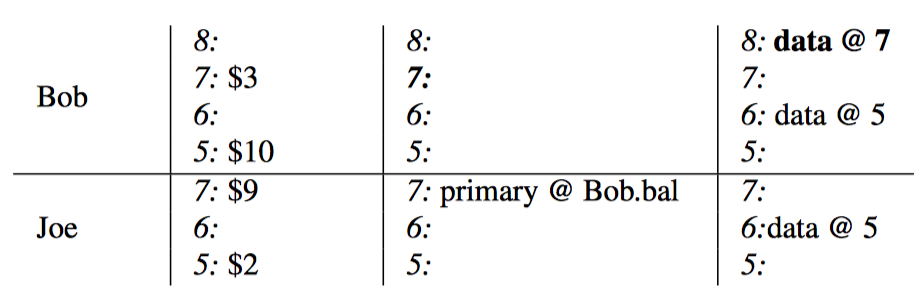
写入逻辑
Prepare
- 检查自startts之后是否有新的write值,如果存在,表示有其它事务已经提交,故回滚本事务
- 检查是否有lock,如果有,表示其它事务已经上锁,回滚,故存在两个事务同时发现互相被锁的情况,导致两个事务都被回滚
- 对数据上锁lock字段,并写入data字段。
两阶段Commit
- primary写入write字段
- 清理primary的lock数据
- secondaries写入write字段
- 清理secondaries的lock数据
如果在1,2之间client挂掉,则回滚所有事务。
如果在2之后client挂掉,则forward所有事务。
对于要查找的数据,如果发现lock状态且client不活跃了,说明client异常退出,
需要根据primary的状态就行回滚或者forward。
读取逻辑
- 查看是否存在lock,存在则等待lock释放
- 获取[0,startts]的write
一个事务中的两个GET如何保证读取的数据是一致的?
TRX1 GET1 GET2
TRX2 SET1 SET2
- 如果TRX1和TRX2不相交,串行的话,数据是一致的。
- 如果GET1在LOCK1之前,读取老的数据,GET2在LOCK2之后,GET2被阻塞,但是SET2和SET1的committs必然大于TRX1,故GET2结束阻塞后,读取到的是老数据,和GET1版本一致。
- 如果GET1被LOCK1阻塞,则等待LOCK1结束,数据的可见性就取决于TRX2的committs的取值,但是数据也是一致的。
故读取必然一致。
事务清理
个人观点
- 与其说Percolator是一个分布式事务系统,不如说Percolator是一个应用程序。
- Percolator在bigtable的基础之上,以第三方库的形式提供服务,这就注定了其分布式事务无法很好的和bigtable原有事务融合,而是建立在bigtable的row transaction的基础之上。
- Percolator的锁的获取与释放,都需要真实的在bigtable上写入具体的数值,如此开销无法接受, 如果改成内存锁性能会有不少提升,但是无法保证故障的时候锁信息的保留。
- 读取看似是不上锁,但是会被lock阻塞,如果存在lock则需要等待lock消失。优化点是可以提前确定committs,然后lock上面带上committs的值,就不用被阻塞了。
- 分布式锁架构,遇到写冲突直接回滚事务,而不是等待锁,规避的死锁检查,但是可能造成大量冲突回滚。
- 由于lock写入库,造成事务回滚代价较大
综上所述,Percolator确实是更贴近其特定应用的一个半通用系统,如果在分布式DBMS上采用此策略,性能可能会出现瓶颈。更好的改进方向是和底层的逻辑存储进行深入融合,将上锁和多版本放到bigtable内部层面, 而不是真实的写入数据。