字符集一直是MySQL让人蛋疼的问题,MySQL8.0将默认字符集定义为utf8mb4,如果一个DBA没有碰到过字符集乱码的问题,那肯定不是一个合格的厨子。
Unicode与UTF-8
Unicode 是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严.
Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
MySQL字符集参数意义
|
|
服务器端设置的参数
character_set_server: create database不指定字符集时,使用此参数的字符集。character_set_database: 不可设置参数,用户表示当前数据库的字符集。USE到不同库时,会变成不同库的字符集。character_set_filesystem: 文件名解析时使用的字符集,比如load data, select into outfile等命令指定文件时会用到。character_set_system: server层存储标识符等用到的字符集,固定utf8.
客户端设置的参数
character_set_client: 用户指定客户端的字符集character_set_connection: 用户指定客户端的字符集character_set_results: 服务器返回给客户端消息之前,会把对应的字段转换成此值所规定的字符集
列的字符集
列的字符集可以使用create table选项进行统一定义,也可以单独对某个列进行定义:
|
|
terminal字符集
除了MySQL的字符集,还有一个字符集比较容易被忽略,那就是终端的字符集,比如terminal、iterm2等终端,都可以设置不同的字符集,用于终端显示的判断。
插入过程字符集转化流程
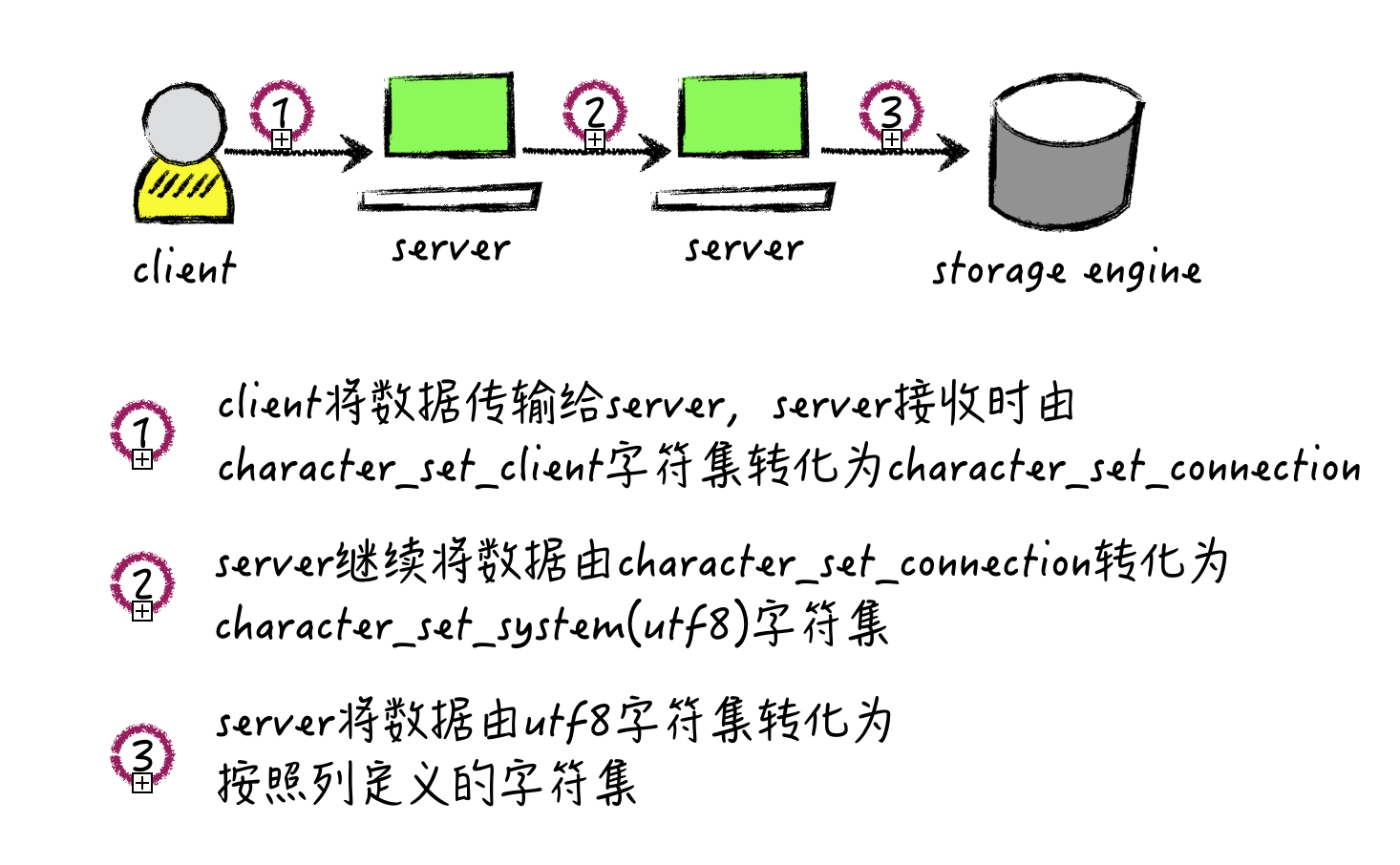
举例分析
中国编码
| 汉字 | Unicode | UTF-8 |
|---|---|---|
| 中 | 4E2D | E4B8AD |
| 国 | 56FD | E59BBD |
插入流程
表定义见列的字符集一节
|
|
- 终端数据同样的汉字,编码相同,均为utf-8编码.
- server将字符按照
character_set_client=latin1解析,转化为character_set_connection=latin1, 由于两个字符集一样,故不做任何转化。 - server将字符按照
character_set_connection=latin1解析,转化为character_set_system=utf8,字符集不同,需要逐字转换- latin1转为unicode, 中国的latin1=E4B8ADE59BBD, 转为unicode=E4B8ADE59BBD
- unicode转为utf-8, unicode转为utf-8为C3A4C2B8C2ADC3A5E280BAC2BD
- server按照列定义字符集进行转化
- c1由utf-8转为latin1,即是上面的逆向转化, 最后存储E4B8ADE59BBD
- c2定义为utf-8,不需要转化,故直接存储C3A4C2B8C2ADC3A5E280BAC2BD
虽然最后终端两个字符都能正常显示,但是在内部存储其实是两种存储格式。
深入源码
character_set_client => character_set_connection
sql_yacc.yy
|
|
character_set_connection => character_set_system
|
|
character_set_system => field charset
|
|